Proposal For A More Scalable Linux Scheduler
by
Davide Libenzi
<[email protected]>
Sat 10/27/2001
Episode [1]
Captain's diary, tentative 2, day 1 ...
The current Linux scheduler has been designed and optimized to be very fast and have a low I/D cache footprint. Inside the schedule() function the fast path is kept very short by moving less probable code out :
if (prev->state == TASK_RUNNING)
goto still_running;
still_running_back:
(fast path follow here)
return;
still_running:
(slow path lies here)
goto still_running_back;
and this is achieved very well as it's shown in the warm cache cycle counter test that follow. The same things could be said for the cache line alignment of critical fields inside the task struct to reduce the number of cache loads/invalidations. While the level of optimization of the current scheduler code is hardly improvable the algorithm that lies behind does not scale very well when the load onto the run queue starts to increase. This because the current code :
[kernel/sched.c]
list_for_each(tmp, &runqueue_head) {
p = list_entry(tmp,
struct task_struct, run_list);
if (can_schedule(p,
this_cpu)) {
int weight = goodness(p, this_cpu, prev->active_mm);
if (weight > c)
c = weight, next = p;
}
}
loops inside the whole list of runnable task and, being the fast
path code length very short, the percentage added on the schedule() cost
for each loop is not irrelevant.
A lot of tentatives have been done to achieve a better scheduler
scalability under high load while keeping untouched the cost of the execution
( in terms of speed and I/D cache footprint ) of the current one when the
load is low. The reason of this "maniacal" focus on the scheduler performance
with low/standard loads is because, and it's hard to not agree, these are
the 90% of cases out there. In the last few years the computer market scenario
is changed, the price of SMP systems dropped significantly and the needs
of a better Linux scalability on SMP machines is become a must. The Linux
adoption done by big computer system manufacturers that use it on large
SMP machines ( and NUMA ) increased the need of a more scalable kernel
scheduler. Enormous improvements has been done to achieve a better scalability
and the initial Big Lock that ruled the initial SMP implementation is spinned
less and less while the kernel version number increase. The most critical
paths have now their own spinlock aiming at a higher parallelism inside
the kernel code. The IRQ distribution between CPUs increased the number
of events that can be handled simultaneously, increasing the potential
load on the scheduler subsystem. Besides the nature of the algorithm, that
is not optimal when the run queue length peak up, there is the presence
of a big ( from a scheduler point of view ) runqueue_lock that forces the
scheduler code execution to be synchronous. It is not hard to show, using
a cycle counter ( a kernel patch is available in Links[2]
), that the effect of a slow path ( the loop, executed with the lock held
) together with the presence of a single, big lock impact the scheduler
perfomance in a significant way on SMP systems. Another less than optimal
behavior of the current SMP scheduler is the way it spins around tasks
among CPUs in the hope to achieve, in this way, the maximum CPU utilization.
The current method of moving processes among CPUs could be valid if 1)
the cost of move ( in terms of cache footprint ) would be zero 2) the speed
of the move would be infinite. Modern CPUs have, and will have even more,
very fast cores that give us strong performance if the CPU finds the data
it needs inside the L1/L2 cache while it becomes a "pain in the butt" when
it has to talk to external memory through the conventional bus. In the
future this scenario is going to be even more true with CPU manufacturers
promising 10-20GHz cores while the prospective outside ( the CPU ) are
not going to be so outstanding. The presence of increasing quantities of
L1 cache to separate the core from the external memory bus will make even
more precious the act of preserving process locality and cache "image".
The hypothesis that the current scheduler use is based on the assumption
that the distance/metric between CPUs is small/low and this concept is
false and is going to be even more false with the next generation of SMP
systems in which high speed cores/caches will be connected by a bus, whose
speed cannot increase without turning the computer in a radio station.
So, a primary goal for a next generation SMP scheduler, should be the try
to preserve the CPU I/D cache footprint of a process as more as possible.
The current scheduler try to statically estimate the cost-of-move by
adding "weight" to the goodness() calculation :
[kernel/sched.c]
static inline int goodness(struct task_struct * p, int this_cpu,
struct mm_struct *this_mm)
{
int weight;
...
#ifdef CONFIG_SMP
/* Give a largish advantage
to the same processor... */
/* (this is equivalent
to penalizing other processors) */
if (p->processor ==
this_cpu)
weight += PROC_CHANGE_PENALTY;
#endif
...
return weight;
}
This can lead to wrong move decisions because a freshly scheduled-out cpu-bound process might see its cache image trashed by an incoming task arriving from another cpu. Another undesired behavior of the current scheduler happens when an odd number of cpu-bound tasks N are run on a M way SMP system with N > M. In this case the cpu bound tasks are rotating between the CPUs by trashing each other cache footprint. This behavior is easily reproducible by using the LatSched kernel patch together with the schedcnt and cpuhog tool that are available in Links[2], running :
# schedcnt -- cpuhog --ntasks N
and looking at the process migration flow. The request of infinite speed ( of the process move ) comes into play because the current scheduler act as an infinite feedback system. When the current scheduler decide the process CPU target, it analyzes the status of the system at the current time without taking in account the status at the previous time values. But the feedback that is sent ( IPI to move the task ) take a finite time to hit the target CPU and, meanwhile, the system status changes. So it's going to apply a feedback calculated in time T0 to a time Tn, and this will result in system auto-oscillation that is perceived as tasks bouncing between CPUs. This is kind of electronic example but it applies to all feedback systems. The solution to this problem, excluding a zero feedback delivery time, is 1) lower the feedback amount, that means, try to minimize task movements 2) a low pass filter, that means, when We're going to decide the sort ( move ) of a task, We've to weight the system status with the one that it had at previous time values. So, another design goal for a modern SMP scheduler, should be to try to avoid process moves as more as possible. To summarize the design goals for a more scalable scheduler should be :
1) Do not impact the performance on UP or light loaded systems
2) Reduce the cost of the full runqueue goodness calculation loop
3) Remove the big runqueue_lock to improve parallelism
4) Minimize process moves through CPUs
The proposed implementation uses a runqueue-per-cpu scheduler where,
inside each CPU, the scheduler code is exactly the same of the current
one. The big runqueue_lock has been substituted by locks that protects
CPU run queues. By having separate run queues the length/cost of the goodness()
loop has been divided by N ( N == number of CPUs ) and the presence of
per-runqueue locks gives the scheduler a full parallelism between the CPUs.
The removal of an high frequency contention lock like runqueue_lock has
the other positive effect to drastically reduce the cache ping/pong between
CPUs and the associated coherency traffic. The cost of the schedule() on
UP/light-loaded system is going to be the same because the scheduler uses
the same code ( inside each run queue ) of the old one. The PROC_CHANGE_PENALTY
disappear because our default is to not move a task and the cost of reschedule_idle()
( that now might lead to an expensive idle discovery loop ) has been cut.
The cut of reschedule_idle() is going to have a big impact because this
function is basically called at every wake_up() and inside the __schedule_tail()
of a still running process, with the big runqueue_lock held. The call to
the reschedule_idle() done in __schedule_tail() has been completely removed
achieving a shorter path respect to the current design. Provided that this
kind of implementation achieve points 1, 2 and 3, how can the number of
moves be minimized by keeping a substantially balanced system ? The proposed
implementation ( right now ) uses two ways to try to keep the system quite
balanced without swapping processes around like crazy. The first one is
done at process creation time ( do_fork() ) that try
to find the more unloaded CPU to assign to p->processor :
[kernel/fork.c]
int do_fork(...) {
...
#ifdef CONFIG_SMP
p->processor = clone_flags & CLONE_PID ?
current->processor: get_best_cpu();
#endif
...
[kernel/sched.c]
int get_best_cpu(void)
{
int nr, best_cpu, this_cpu = smp_processor_id();
int min_nr_running, cpu_running, cpu_processes,
min_nr_processes;
best_cpu = this_cpu;
min_nr_running = atomic_read(&qnr_running(this_cpu));
min_nr_processes = atomic_read(&qnr_processes(this_cpu));
for (nr = 0; nr < smp_num_cpus; nr++) {
if (nr == this_cpu)
continue;
cpu_running = atomic_read(&qnr_running(nr));
if (cpu_running <
min_nr_running) {
min_nr_running = cpu_running;
min_nr_processes = atomic_read(&qnr_processes(nr));
best_cpu = nr;
} else if (cpu_running
== min_nr_running &&
(cpu_processes = atomic_read(&qnr_processes(nr))) < min_nr_processes)
{
min_nr_processes = cpu_processes;
best_cpu = nr;
}
}
return best_cpu;
}
This function is executed without held locks and assign the less loaded CPU to the newly created task. The other form of balancing is done inside the idle task, when the idle is scheduled-in by a becoming-idle CPU :
[arch/*/kernel/process.c]
void cpu_idle (void)
{
/* endless idle loop with no priority at all
*/
init_idle();
current->nice = 20;
current->counter = -100;
while (1) {
void (*idle)(void) =
pm_idle;
if (!idle)
idle = default_idle;
while (!current->need_resched)
idle();
schedule();
check_pgt_cache();
#ifdef CONFIG_SMP
runqueue_balance(IDLE_RQBALANCE);
#endif /* #ifdef CONFIG_SMP */
}
}
The function runqueue_balance() try to find the more loaded CPU and try to steal a process from there :
[kernel/sched.c]
static inline int try_steal_task(int src_cpu, int dst_cpu)
{
int res = 0;
unsigned long flags;
struct task_struct *tsk;
struct list_head *head, *tmp;
spin_lock_irqsave(&runqueue_lock(src_cpu),
flags);
head = &runqueue_head(src_cpu);
list_for_each(tmp, head) {
tsk = list_entry(tmp,
struct task_struct, run_list);
if (can_schedule(tsk,
dst_cpu) && !tsk->move_to_cpu) {
tsk->move_to_cpu = dst_cpu + 1;
res = 1;
break;
}
}
spin_unlock_irqrestore(&runqueue_lock(src_cpu),
flags);
return res;
}
int runqueue_balance(int mode)
{
int nr, crun, this_cpu = smp_processor_id(),
max_nr_running = 0, max_cpu = 0;
for (nr = 0; nr < smp_num_cpus; nr++) {
if (nr == this_cpu)
continue;
if ((crun = atomic_read(&qnr_running(nr)))
> max_nr_running) {
max_nr_running = crun;
max_cpu = nr;
}
}
if (max_nr_running > (atomic_read(&qnr_running(this_cpu))
+ 1))
try_steal_task(max_cpu,
this_cpu);
return 0;
}
This is a very simple function that loops without held locks and ( in this implementation ) if the maximum found run queue length is greater than the run queue of the current CPU plus one, it tries to steal a process. By stealing a task that is currently inside the source CPU run queue increase the probability that the selected process is CPU bound. Since the speed of this function is not too critical, better implementations could be coded to try to keep in account cache localities and friends. Another form of balancing could be included in try_to_wake_up() in case the task's CPU run queue length goes above a certain limit, by calling an idle-discovery and wakeup function. But the proposed scheduler, as is, achieve a very good balancing by only using the get_best_cpu() at do_fork() time and the runqueue_balance() at cpu_idle() kicks in. The actual move of the process is done in one of the slow paths of schedule() by doing :
[kernel/sched.c]
#ifdef CONFIG_SMP
if (next->move_to_cpu)
goto cpu_migrate;
cpu_migrate_back:
#endif /* #ifdef CONFIG_SMP */
This kind of solution, instead of a direct move inside runqueue_balance(), has been chosen because the "next" tasks that is selected is probably the one that has been absent from the CPU for the longer period of time, hence having the lower cache footprint on its current CPU. Another optimization has been added to the proposed scheduler and it's the concept of "CPU History Weight". The current scheduler does not keep in account that a CPU bound task that is currently scheduled-out should have an advantage-weight over the other ones because it's the one that probably have the more "convenient" cache image. The patch tracks the number of jiffies that a task run as :
JR = Jout - Jin
where Jin is the jiffies value when the task in kicked in and Jout is the time when it's kicked out. In a given time the value of the footprint is :
W = JR > (J - Jout) ? JR - (J - Jout): 0
where J is the current time in jiffies. This means that if the task
is run for 10 ms, 10 ms ago, it's current weight will be zero. This is
quite clear because the more a process does not run the more footprint
will lose. The choice of jiffies against CPU dependent performance counter
is because 1) jiffies are in the same "measure unit" of weight 2) their
resolution is enough to catch CPU bound tasks 3) machine integer code is
cheaper than double-integer one 4) there's no CPU dependency. This method
is not going to affect the traditional high priority given to I/O bound
tasks because the presence of CPU bound ones will force an higher counter
recalculation frequency that add "weight" to the out-of-runqueue I/O bound
processes. The test these numbers refer to have been done on an Athlon
1GHz 256Mb RAM ( UP system ) and a dual PIII 733MHz 256Mb RAM ( 2W-SMP
). The first part of the test is to show the the new scheduler does not
impact UP/light-loaded systems and, eventually, improve its behavior. Strictly
speaking I was pretty sure that the UP performance did not change because
of the same code but, You know, numbers are better than any talks. The
second part of the test analyzes the performance/behavior of the proposed
scheduler on a 2 way SMP system. It's pretty obvious that the performance/behavior
gain is going to be even higher on bigger N-SMP system ( N >= 4 ). For
these tests are used tools available in Links[2] and
exactly the LatSched ( cycle counter/process migration ) kernel patch,
the schedcnt program to collect LatSched samples, lat-sched
to simulate in-Icache scheduler timings and my favourite/high tech
cpuhog software to create CPU bound tasks. The first test sample
the scheduler while it's stressed by the lat-sched tool that
creates a bunch of processes ( clone() ) and makes them switch using sys_sched_yield()
under different values of cache drain size.
The test is run with :
# schedcnt --ttime 12 -- lat-sched --ttime 20 --size S --ntasks N
Since different sizes S did not change the overall picture I'll
report only the one with zero size just to show how fast is the common
path with 1-2 tasks on the run queue.
The new scheduler without the "CPU history" evaluation perfom exactly
like the old one and the very small noise on the measure is sufficent to
keep results not distinguishable. The "CPU history" evaluation add a few
cycles to the fast path but 1) these are vanishing when a real world switch
test is done ( see next test) 2) the better behavior it gives ( see other
test ) fully justify its presence.
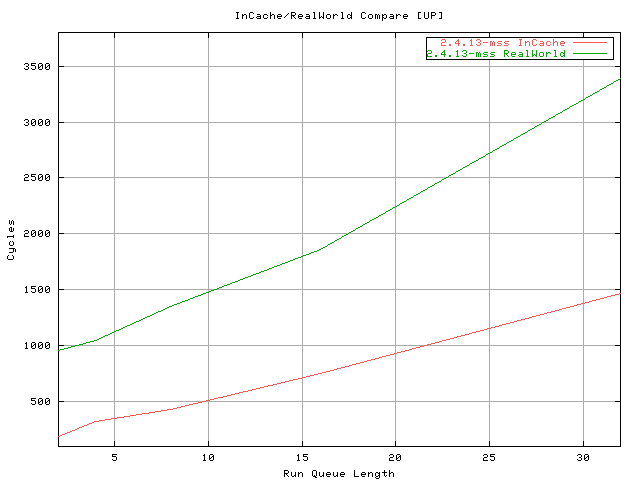
With the next test a real world switching test is done by measuring, through the cycle counter, the scheduler timings with different run queue loads ( thanks to cpuhog ) :
# shcedcnt --ttime 30 -- cpuhog --ttime 40 --size S --ntasks N
This test basically loads the run queue with cpuhog
and sample the scheduler cycles when dealing with my machine tasks switches.
The same number/type of processes that are run and the high number of samples
( > 8000 ) collected are enough to stabilize the measure ( five samples,
minor / major out, average of three ). Comparing this test with the previous
one the cost of cache footprints and TLB flushing are evident. The number
of cycles spent by the scheduler is about 3-4 times the one measured with
the previous test. Even this test shows basically the same results when
comparing the current with the proposed scheduler.

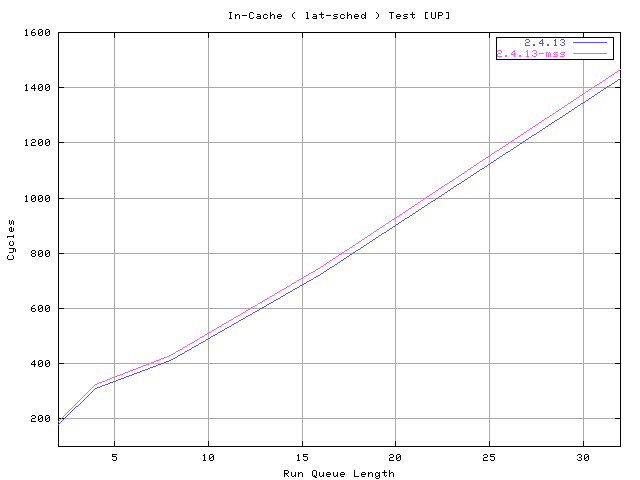
The next test run with the command :
# schedcnt --ttime 12 -- lat-sched --ttime 20 --ntasks N
compare the performance of the current and the proposed scheduler
on my dual PIII 733 256Mb RAM machine. The first time I ran the test I
thought to have screwed up something so I ran it again, again and again,
checking the full dump of schedcnt. Three factors comes into play
to explain this kind of performance improvement 1) the run queue splitting
cut the cost of the goodness() loop 2) the removal of the runqueue_lock
in favor to CPU local locks make the schedule() code execution asynchronous
3) the removal of the reschedule_idle() from __schedule_tail() that is
always called during this test because the scheduled test status is always
TASK_RUNNING. The reason I started from a run queue length of 4 is because
lat-sched uses sys_sched_yield() to switch and this, in the latest
kernels, has an optimization that avoid setting need_resched under low
run queue length.
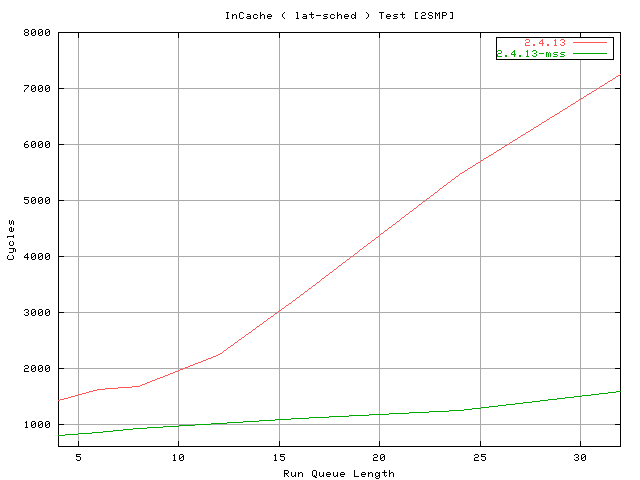
The next test is to show the effect of the "CPU history" weight on the scheduler behavior using the classical example of the couple of CPU bound tasks with the keyboard ticking. The test is run with :
# schedcnt --time 4 -- cpuhog --time 8 --ntasks 2
This is the sample output that I get from my Athlon machine with
the current scheduler ( CPU bound tasks are 906 & 907 ) :
| CYSTART | CYEND | SCHCY | PID | PRUN | |
| 349876575364 | 349876602805 | 27441 | 907 | 29589992 | <<< |
| 349906165356 | 349906165829 | 473 | 2 | 5829 | |
| 349906171185 | 349906171706 | 521 | 906 | 20197311 | |
| 349926368496 | 349926370256 | 1760 | 748 | 14835 | |
| 349926383331 | 349926384174 | 843 | 807 | 13301 | |
| 349926396632 | 349926397786 | 1154 | 809 | 142885 | |
| 349926539517 | 349926541394 | 1877 | 810 | 118519 | |
| 349926658036 | 349926658951 | 915 | 811 | 117994 | |
| 349926776030 | 349926777235 | 1205 | 786 | 10647 | |
| 349926786677 | 349926787473 | 796 | 907 | 15178469 | |
| 349941965146 | 349941966201 | 1055 | 2 | 8495 | |
| 349941973641 | 349941973993 | 352 | 907 | 24373097 | |
| 349966346738 | 349966347192 | 454 | 906 | 11417181 | |
| 349977763919 | 349977764499 | 580 | 2 | 4655 | |
| 349977768574 | 349977768873 | 299 | 906 | 18564042 | |
| 349996332616 | 349996358560 | 25944 | 906 | 18046874 | <<< |
| 350014379490 | 350014380000 | 510 | 2 | 4834 | |
| 350014384324 | 350014384717 | 393 | 907 | 35020619 | |
| 350049404943 | 350049405243 | 300 | 2 | 4396 | |
| 350049409339 | 350049410030 | 691 | 906 | 35913388 | |
| 350085322727 | 350085322985 | 258 | 2 | 4145 | |
| 350085326872 | 350085327224 | 352 | 906 | 10960739 | |
| 350096287611 | 350096288169 | 558 | 907 | 19989164 | |
The lines marked with <<< are where the scheduler falls
in the recalculation loop whose cost, in this environment, is about 25000
cycles ( schedule + recalc ). It's clear the swapping done by the keventd
task ( PID == 2 ) on the CPU bound tasks ( 906 & 907 ). This is the
same test run on the same system with the proposed implementation
and the "CPU history" active :
| CYSTART | CYEND | SCHCY | PID | PRUN | |
| 144122652482 | 144122679190 | 26708 | 846 | 13991469 | <<< |
| 144136643951 | 144136644317 | 366 | 2 | 4463 | |
| 144136648414 | 144136648791 | 377 | 846 | 35796349 | |
| 144172444763 | 144172445286 | 523 | 2 | 4626 | |
| 144172449389 | 144172449724 | 335 | 846 | 10175255 | |
| 144182624644 | 144182625060 | 416 | 847 | 26318489 | |
| 144208943133 | 144208943722 | 589 | 2 | 4731 | |
| 144208947864 | 144208948177 | 313 | 847 | 33648818 | |
| 144242596682 | 144242623219 | 26537 | 847 | 59972040 | <<< |
| 144302568722 | 144302569336 | 614 | 2 | 6388 | |
| 144302575110 | 144302575613 | 503 | 846 | 13212070 | |
| 144315787180 | 144315787506 | 326 | 2 | 4370 | |
| 144315791550 | 144315791827 | 277 | 846 | 36511145 | |
| 144352302695 | 144352303222 | 527 | 2 | 4628 | |
| 144352307323 | 144352307612 | 289 | 846 | 10233439 | |
| 144362540762 | 144362567004 | 26242 | 846 | 24886389 | <<< |
| 144387427151 | 144387427811 | 660 | 2 | 4752 | |
| 144387431903 | 144387432241 | 338 | 846 | 35080899 | |
| 144422512802 | 144422513179 | 377 | 847 | 715629 | |
| 144423228431 | 144423229017 | 586 | 2 | 4679 | |
| 144423233110 | 144423233404 | 294 | 847 | 35796611 | |
| 144459029721 | 144459030024 | 303 | 2 | 4440 | |
| 144459034161 | 144459034651 | 490 | 847 | 23451401 | |
# schedcnt --time 4 -- cpuhog --time 8 --ntasks 2
| CYSTART | CYEND | SCHCY | PID | PRUN |
| [CPU#0] | ||||
| 48929327333 | 48929328366 | 1033 | 687 | 1838865 |
| 48931166198 | 48931172609 | 6411 | 687 | 43978613 |
| 48975144811 | 48975146639 | 1828 | 688 | 73297834 |
| 49048442645 | 49048447977 | 5332 | 688 | 43978737 |
| 49092421382 | 49092423347 | 1965 | 689 | 65968023 |
| 49158389405 | 49158394685 | 5280 | 689 | 43978732 |
| 49202368137 | 49202370092 | 1955 | 687 | 65968039 |
| 49268336176 | 49268341244 | 5068 | 687 | 43978726 |
| 49312314902 | 49312316802 | 1900 | 688 | 65968029 |
| 49378282931 | 49378288207 | 5276 | 688 | 43978731 |
| 49422261662 | 49422263672 | 2010 | 689 | 65968034 |
| 49488229696 | 49488234692 | 4996 | 689 | 43978715 |
| 49532208411 | 49532210380 | 1969 | 687 | 65968045 |
| 49598176456 | 49598181562 | 5106 | 687 | 43978726 |
| 49642155182 | 49642157104 | 1922 | 688 | 65968023 |
| 49708123205 | 49708128329 | 5124 | 688 | 43978726 |
| 49752101931 | 49752103826 | 1895 | 689 | 65968034 |
| 49818069965 | 49818075047 | 5082 | 689 | 43978726 |
| 49862048691 | 49862050525 | 1834 | 687 | 65968045 |
| 49928016736 | 49928021842 | 5106 | 687 | 43978715 |
| 49971995451 | 49971997335 | 1884 | 688 | 65968045 |
| 50037963496 | 50037968642 | 5146 | 688 | 43978726 |
| 50081942222 | 50081944155 | 1933 | 689 | 65968034 |
| 50147910256 | 50147915217 | 4961 | 689 | 43978715 |
| 50191888971 | 50191890882 | 1911 | 687 | 65968034 |
| [CPU#1] | ||||
| 48884378625 | 48884391982 | 13357 | 686 | 160770 |
| 48884539395 | 48884541768 | 2373 | 688 | 41737542 |
| 48926276937 | 48926279123 | 2186 | 689 | 65968054 |
| 48992244991 | 48992251671 | 6680 | 689 | 43978645 |
| 49036223636 | 49036225826 | 2190 | 687 | 65968062 |
| 49102191698 | 49102197224 | 5526 | 687 | 43978698 |
| 49146170396 | 49146172537 | 2141 | 688 | 65968056 |
| 49212138452 | 49212143962 | 5510 | 688 | 43978704 |
| 49256117156 | 49256119089 | 1933 | 689 | 65968056 |
| 49322085212 | 49322090185 | 4973 | 689 | 43978704 |
| 49366063916 | 49366065860 | 1944 | 687 | 65968062 |
| 49432031978 | 49432037378 | 5400 | 687 | 43978698 |
| 49476010676 | 49476012703 | 2027 | 688 | 65968056 |
| 49541978732 | 49541984085 | 5353 | 688 | 43978704 |
| 49585957436 | 49585959380 | 1944 | 689 | 65968056 |
| 49651925492 | 49651931135 | 5643 | 689 | 43978704 |
| 49695904196 | 49695906223 | 2027 | 687 | 65968056 |
| 49761872252 | 49761877418 | 5166 | 687 | 43978704 |
| 49805850956 | 49805852939 | 1983 | 688 | 65968056 |
| 49871819012 | 49871824305 | 5293 | 688 | 43978710 |
| 49915797722 | 49915799715 | 1993 | 689 | 65968050 |
| 49981765772 | 49981770789 | 5017 | 689 | 43978704 |
| 50025744476 | 50025746420 | 1944 | 687 | 65968056 |
Now the CPU bound tasks are 687, 688 and 689 and the current scheduler keeps swapping them between the two CPUs. Let's see the same test, on the same machine, with the proposed scheduler running :
| CYSTART | CYEND | SCHCY | PID | PRUN |
| [CPU#0] | ||||
| 218723461722 | 218723466324 | 4602 | 690 | 4867536 |
| 218728329258 | 218728331618 | 2360 | 690 | 15921370 |
| 218744250628 | 218744251994 | 1366 | 2 | 6157 |
| 218744256785 | 218744257526 | 741 | 690 | 28058989 |
| 218772315774 | 218772317862 | 2088 | 690 | 43986596 |
| 218816302370 | 218816304297 | 1927 | 690 | 43986613 |
| 218860288983 | 218860290894 | 1911 | 690 | 43986630 |
| 218904275613 | 218904277463 | 1850 | 690 | 43986629 |
| 218948262242 | 218948264203 | 1961 | 690 | 43986624 |
| 218992248866 | 218992250712 | 1846 | 690 | 43986613 |
| 219036235479 | 219036237462 | 1983 | 690 | 43986624 |
| 219080222103 | 219080223926 | 1823 | 690 | 43986624 |
| 219124208727 | 219124210638 | 1911 | 690 | 43986635 |
| 219168195362 | 219168197191 | 1829 | 690 | 43986624 |
| 219212181986 | 219212183952 | 1966 | 690 | 43986613 |
| 219256168599 | 219256170527 | 1928 | 690 | 43986635 |
| 219300155234 | 219300157134 | 1900 | 690 | 43986616 |
| 219344141850 | 219344143687 | 1837 | 690 | 43986621 |
| 219388128471 | 219388130404 | 1933 | 690 | 43986624 |
| 219432115095 | 219432116918 | 1823 | 690 | 43986624 |
| [CPU#1] | ||||
| 218705750104 | 218705751979 | 1875 | 688 | 17704450 |
| 218723454554 | 218723460984 | 6430 | 689 | 7331208 |
| 218730785762 | 218730789304 | 3542 | 689 | 43986195 |
| 218774771957 | 218774772941 | 984 | 688 | 43986602 |
| 218818758559 | 218818761210 | 2651 | 688 | 43986635 |
| 218862745194 | 218862746086 | 892 | 689 | 43986624 |
| 218906731818 | 218906734442 | 2624 | 689 | 43986624 |
| 218950718442 | 218950719244 | 802 | 688 | 43986630 |
| 218994705072 | 218994707663 | 2591 | 688 | 43986596 |
| 219038691668 | 219038692499 | 831 | 689 | 43986646 |
| 219082678314 | 219082680891 | 2577 | 689 | 43986635 |
| 219126664949 | 219126665664 | 715 | 688 | 43986613 |
| 219170651562 | 219170654115 | 2553 | 688 | 43986630 |
| 219214638192 | 219214638990 | 798 | 689 | 43986607 |
| 219258624799 | 219258627299 | 2500 | 689 | 43986635 |
| 219302611434 | 219302612128 | 694 | 688 | 43986635 |
| 219346598069 | 219346600617 | 2548 | 688 | 43986624 |
| 219390584693 | 219390585486 | 793 | 689 | 43986613 |
| 219434571306 | 219434573905 | 2599 | 689 | 43986602 |
| 219478557908 | 219478558654 | 746 | 688 | 43986646 |
| 219522544554 | 219522547074 | 2520 | 688 | 43986624 |
In this case the scenario is significantly improved with one task
sticked on one CPU and the other two sharing the remaining CPU.
To be continued ...
Scheduler:
xsched-2.4.13-0.10.diff
Scheduler + LatSched:
xsched+lats-2.4.13-0.11.diff
1) Linux Kernel:
http://www.kernel.org/
2) My Linux Scheduler Stuff Page:
http://www.xmailserver.org/linux-patches/lnxsched.html
3) Linux Scheduler Scalability:
http://lse.sourceforge.net/scheduling